Categories
- Reliability
- The system should continue to work correctly, even in the face of adversity (hw or sw faults)
- Scalability
- As the system grows, there should be reasonable ways of dealing with that growth
- Maintanability
- Over time, many different people should be able to work on the system productively.
Reliability
Systems should be fault-tolerant or resilient. Basically we need to design systems so that faults (one component stops working) do not lead to failures (whole system stops working).
Hardware fails all the time, we can prevent this by adding redundancy to the individiaul hw components, (set up disks in a RAID config, add dual power supplies to servers, hot-swappable cpus, etc). With cloud computing, we need to move toward systems that can tolerate the loss of entire machines (cloud platforms are now designed to prioritize flexibility and elasticity over single-machine reliability).
Software faults are also common and usually lie dormant for a long time until they are triggered by an unusual set of circumstances. We should carefully think about assumptions and interactions in the system, test thoroughly, process isolation, allowing processes to crash and restart, monitor applications, etc.
A lot of failures are also caused by human errors (e.g. wrong config). Prevent this by designing systems in a way that minimizes opportunity for error (good UX).
Scalability
If the system grows in a particular way, what are our options for coping with the growth? How can we add computing resources to handle the additional load?
Current load on a system can be described with a few numbers called load parameters. And these vary by system.
Here’s an example, Twitter, using data from 2012:
- Twitter has 2 main operations:
- Post tweet: a user can publish a new message to their followers (4.6k reqs/sec on avg or 12k reqs/sec at peak)
- Home timeline: a user can view tweets posted by their follwoers (300k reqs/sec)
- Simply handling 12k reqs/sec would be easy. Hard scaling challenge is the fan-out (each user follows and is followed by many) of these operations.
- Here’s two ways of implementing these:
- Posting a tweet inserts the new tweet into a global collection of tweets. To request the timeline:
SELECT tweets.*, users.* FROM tweets JOIN users ON tweets.sender_id = users.id JOIN follows on follows.followee_id = users.id WHERE follows.follower_id = current_user- Maintain a cache for each user’s home timeline. When a user posts a tweet, look up all the people who follow that user, and insert the new tweet into each of their home timeline caches.
- Twitter changed from option 1 to option 2. This is because the average rate of tweet published tweets is almost two order of magnitudes lower than the rate of home timeline reads.
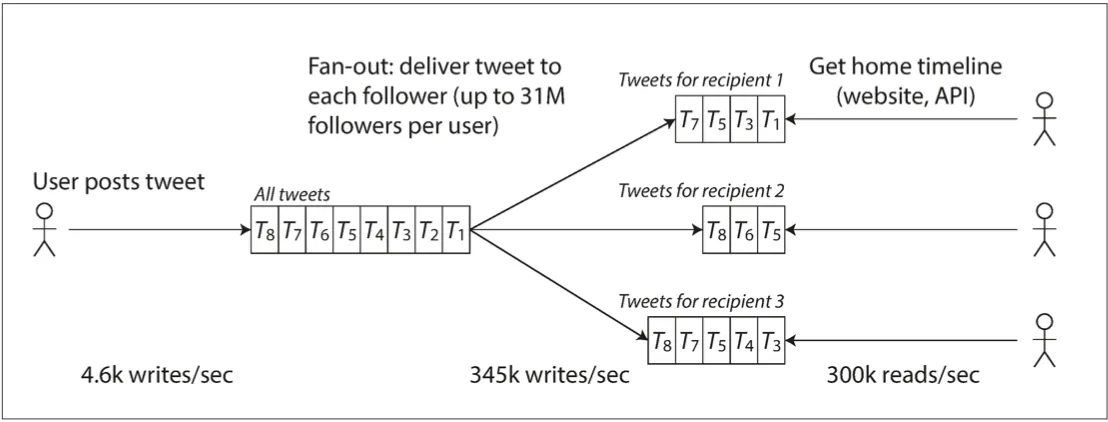
- Right now, Twitter uses a hybrid approach. For most people, tweets continue to be fanned out, except for celebrities. Users home timelines will fetch celebrities tweets separately and merged with the timeline when read.
- This avoid the issue of writing to million of users’ caches when a celebrity posts a tweet.
Describing performance
- Throughput: number of records we can process per second, or total time it takes to run a job on a dataset of a certain size.
- Response time: the time between a client sending a request and receiving a response.
- VS lantency? Not synonyms. Response time is what the client sees. Latency is the duration that a request is waiting to be handled.
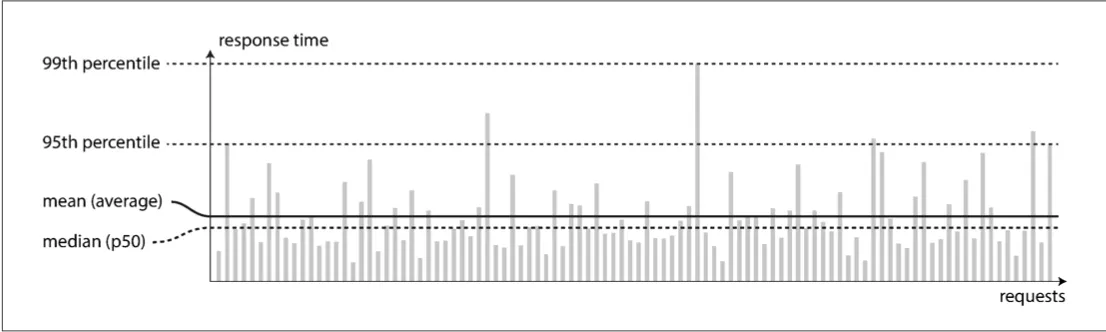 Using percentiles (and the median which is p50) is a why of dealing with ouliers. X p95 means 95% of response times are faster than X.
Using percentiles (and the median which is p50) is a why of dealing with ouliers. X p95 means 95% of response times are faster than X.
Service Level Objective (SLO) and Service Level Agreement (SLA), contracts that define the expected performance and availability of a service. An SLA may state that the service is considered to be up if it has a median response time of less than 200ms and a 99th percentile under 1 s. And service may be required to be up at least 99.9% of the time.
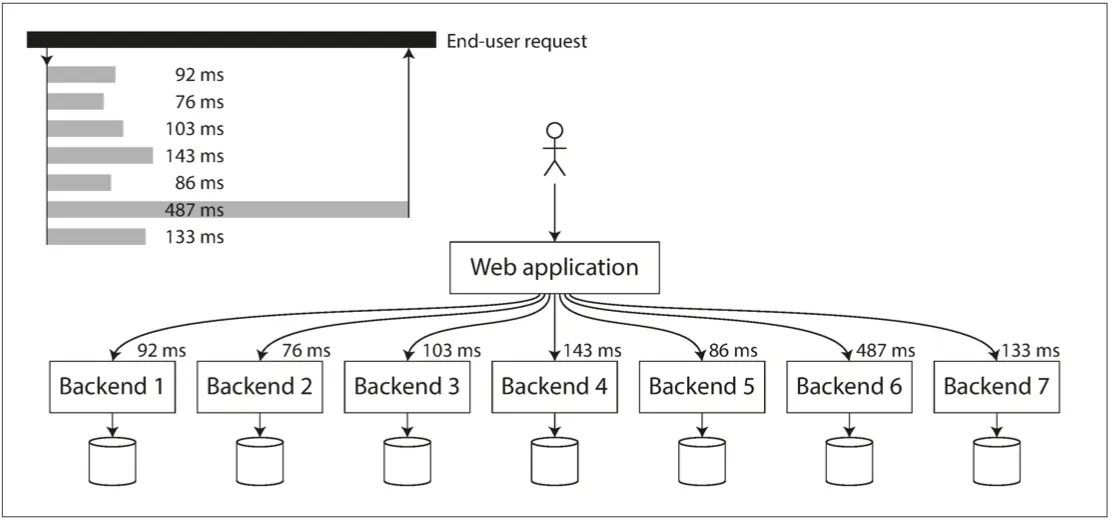
Tail latency amplification: if you have your request needs to call multiple backend service, each service increases the probability of your request being slow (it takes just 1 slow request and it can queue up a service).
Coping with Load
Machines can scale up or scale our or both. An elastic system is one that adds computing resources when they detect a load increase, whereas other systems are scaled manually by a human. Architectures of systems (and the way they scale) is very system dependent, as well as dependent on the load parameters.
Maintainability
Majority of cost of software development is for maintaining an existing system. To minimize pain during maintenance, here’s three design principles:
Operability
Make it easy for operations team to keep the system running smoothly. Operations teams responsibilities: monitor health of system and quickly restore service if it goes in a bad state. Tracking down the cause of problems. Keeping software/platforms up to date. Keep tabs on how different systems affect each other. Anticipate future problems, establish good practices for deploying stuff, etc…
Systems should then make routine tasks easy, allowing the ops teams to focus on high-value activities. Good systems should provide visibility into the runtime behavior of systems. Provide support for automation, avoid dependency on individual machines, provide good docs, etc.
Simplicity
Make it easy for new engineers to understand the system, by removing as much complexity as possible from the system.
Sometimes systems suffer from accidental complexity. Which is complexity that’s not inherent to the problem that the software solves, but only arises from the implementation. We can solve accidental complexity by abstraction. A good abstraction can hide a great deal of implementation behind a clean and clear façade. Can also be reused.
Evolvability
Make it easy for engineers to make changes to the system in the future, allowing for unanticipated use cases as requirements change. Agile frameworks alongside its technical tools like TDD and refactoring cna help. But more importatly the easy with which you can modify a system is linked to its simplicity and abstractions.