Categories
Relational vs Document
Data is organized into relations which are unordered collections of tuples (rows in SQL).
Motives for NoSQL:
- need for greater scalability than relational dbs can achieve, including very large datasets or very high write throughput.
- a widespread preference for free and open source software
- specialized query operations ???
- relational schemas too restrictive
Object-Relational Mismatch
Since most of app development is done in OOP, there has to be an awkward translation layer between the relational tables and the objects in app code. Object-relational mapping (ORM) frameworks like ActiveRecord help with reducing boilerplate code for this.
Let’s say we wanted to model a linkedin profile in a relational database. One-to-many relationship between user profiles and their experience. Traditionally, the experience would be its own table. Then, SQL added support for XML data in the same row and the ability to query and index it. PostgreSQL also supports JSON. A third option would be to save it as JSON but then have the application decode it. No indexing in this case though.
A JSON model like mongodb would reduce the impendance mismatch between app code and storage layer. It also has better locality than a multi-table schema. One query to fetch everything you need.
Sometimes we need to normalize data in relational databases. For examples, possible locations (cities) are stored in a separate table then we have a many-to-many relationship between locations and users. This would not (!) be possible with document models. Since document models can’t really do joins, the responsibility of joining tables shifts to the application code.
History repeats itself: network vs relational
The same challenges of document models today were faced by network models in the past. Network models basically have entities have pointers to other entities. Then you just traverse a graph to fetch the entity you want. Hard thing is you need to keep different access paths in memory at all times.
The relational model just laid out all the data in the open. Relational models have query optimizers that deal with access paths for you and stuff.
Relational vs Document (focusing on data model only)
Document DBs have better schema flexibility, performance due to locality and for some apps, the data model is closer to the data structures used by the application. On the other hand, relational dbs provide better support for joins and many-to-one / many-to-many relationships.
Which one leads to simplest schema?
Document if the data already has a document-like structure (a tree of one-to-many relationships, where typically the entire tree is loaded at once). If the document is too deeply nested that’s a problem as you cannot refer to a nested item within the document, but you instead have to use fields and indices. Poor support for joins may or may not be a problem.
Schema flexibility in document model
It’s not that document models are schema less, because the code usually assumes some kind of schema when reading the data. More accurate to say that it’s schema-on-read instead of schema-on-write (traditional approach of relational dbs, where the schema is explicit and the db ensures all written data conforms to it).
Schema on read is like dynamic typing in programming languages, where schema on write is like static type checking. For example changing the format of a schema with already existing data:
- document dbs, start writing new data with the new format and add app code to handle the old format

- relational dbs, you gotta make a migration

Schema on read advantageous if items in collection dont all have the same structure (data is heterogeneous).
Data locality
A document is usually stored as a single continuous string encoded as JSON or binary such as BSON. This makes it efficient to access the document because you dont need a bunch of index lookups and what not. This is only good if the document isnt too big. Otherwise youd have to fetch it all even for small reads/modifications.
Google Spanner and Bigtable (like Cassandra) also provide data locality with relational schemas tho.
Query Languages
Declarative languages (SQL or even CSS) hide implementation details, they specify the pattern of the data you want not how you want to achieve that goal, like imperative languages. This is good because SQL can improve performance behind the scenes without worrying about whether that will break people’s code or not. Declarative languages also lend themselves to parallel execution. It’s harder for imperative languages since they have such a strict order.
MapReduce Querying
MapReduce is a programming model for processing large amounts of data in bulk across many machines.
Here’s how MongoDB implements it:
 The map function emits a key-value pairs and these will then be grouped by key.
The reduce function is then called once.
The map and reduce functions must be pure functions and this allows them to be run anywhere, in any order and be rerun on failure. Perfect for distributed execution on a cluster of machines.
The map function emits a key-value pairs and these will then be grouped by key.
The reduce function is then called once.
The map and reduce functions must be pure functions and this allows them to be run anywhere, in any order and be rerun on failure. Perfect for distributed execution on a cluster of machines.
This shares the same negatives of any other imperative language though. MongoDB added support for a declarative query language called the aggregation pipeline. The same query would look like this:

Graph-Like Data Models
If our data primarily has many-to-many relationships we should use a graph to store it (social graph, the web, road/rail networks, …). Data doesnt even need to be homogenous, there can be different types of vertices (people, locations, events) and different types of edges (who’s friends with who, who lives where, who attented which event) in the same graph.
Property Graph model\
Each vertex consists of:
- A unique ID
- A set of outgoing edges
- A set of incoming edges
- A collection key-value pairs
Each edge consists of:
- A unique ID
- The tail vertex (where it starts)
- The head vertex (where it ends)
- A label to describe relationship between the two vertices
- A collection key-value pairs
This allows us of having heterogeneous data with different level of granularity of data while still maintaining a clean model. A graph can easily be extended to accomodate changes in your application’s data structures.
The Cypher Query Language
Declarative QL for graphs created for the Neo4j graph db.
 Cypher query to find people who emigrated from the US to Europe:
Cypher query to find people who emigrated from the US to Europe:
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name
As is typical for a declarative query language, the query optimizer will automatically choose the most efficient strategy to executing that query. It could scan all people in the database, examine their birthplace / residence, or it could start from the US and NA and work backwards (with a BFS of some sorts).
Graph Queries in SQL
We can store all vertices in a table and all edges in another table. How do we query a graph like this tough? How to represent WITHIN\*0..? Meaning, follow this edge 0 or more times.
SQL introduced recursive common table expressions that can express the idea of variable-length traversal paths.
 4 lines of code vs 29 lines of code LOL.
4 lines of code vs 29 lines of code LOL.
Triple Store Model
In a triple store, all information is stored in the form of very simple three-part statements (subject, predicate, object). The subject is a vertex and the object can either be a value in a primitive datatype or another vertex.
 As you can see the predicate can either be an edge or a property.
As you can see the predicate can either be an edge or a property.
You can use a semicolon to not repeat yourself.

SPARQL, RDF and the Semantic Web
The semantic web was a project to combine all internet websites into a computer readable web of data. Nothing really came out of it, but we got a few good tools regarding graphs.
RDF (Resource Description Framework) was intended as a mechanism for different websites to publish data in a consistent format.
The Turtle language we saw earlier is a human-readable format for RDF data, RDF only uses URI for referring to vertices and edges.
SPARQL is a query language for triple stores using the RDF data model.
Here’s how the same query, “finding people who emigrated from the US to Europe”, looks like:

Datalog
Datalog is one of the oldest graph QL, it provides the foundation that other QLs built upon.
Its data model is similar to the triple-store model, and Datalog is a subset of Prolog so it shares similarities.
 That’s how we define the model, predicate(subject, object)
That’s how we define the model, predicate(subject, object)
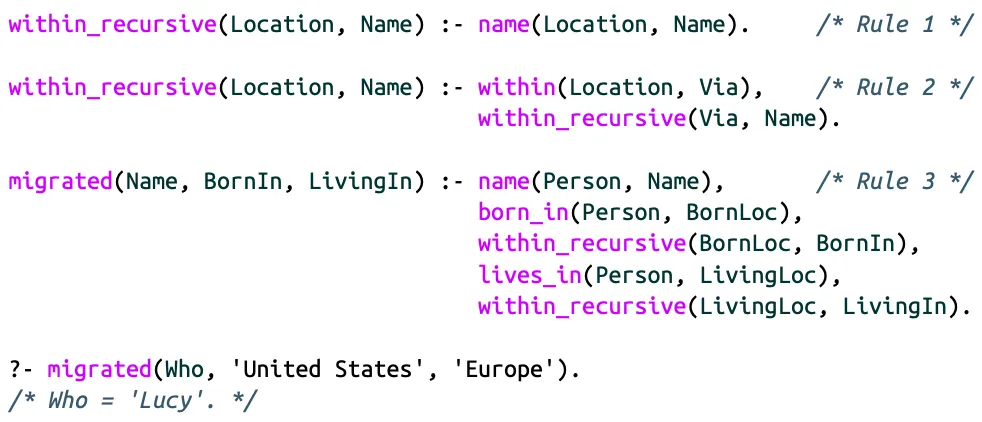 We basically define rules that tell the DB about new predicates.
We basically define rules that tell the DB about new predicates.