The Perceptron
Before neural networks, we had a perceptron -> a single neuron that makes a binary decision.
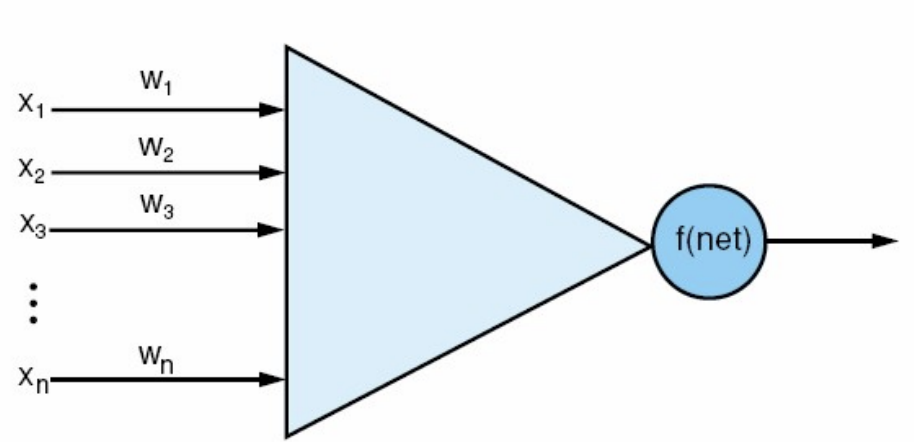
(linear algebra sidenote: dot product is because you can only do dot product of two matrices (m * n) and (p * q) if n = p)
A perceptron is a linear classifier. If we have a line that separates two classes:
- the weights decide the orientation of that line
- the bias decides where it sits (the offset)
- the perceptron output decides which side of the line the input lies on
It only works for linearly separable problems (where you can separate the two classes with a straight line) -> AND, OR, but not a XOR They can’t handle complex data.
Neural Networks
Each neuron computes two things:
- a linear function of the inputs
- a non-linear function of that result -> activation function
So, each layer has two steps:
- linear operator: multiply by weights ->
- pointwise nonlinearity: apply activation function to each element -> So a NN is just a repeated composition of these two steps:
We need an activation function that’s:
- non-linear: allows the model to learn complex, curved relationships, not straight lines
- differentiable functions: smooth enough that we can compute the gradients for training - so that backpropagation works
recall perceptron’s function:
- non-linear (because it jumps from 0 -> 1),
- BUT it’s not differentiable (cant compute gradient at the jump)
example of non-linear + differentiable functions:
- Sigmoid:
- tanh:
- ReLU:
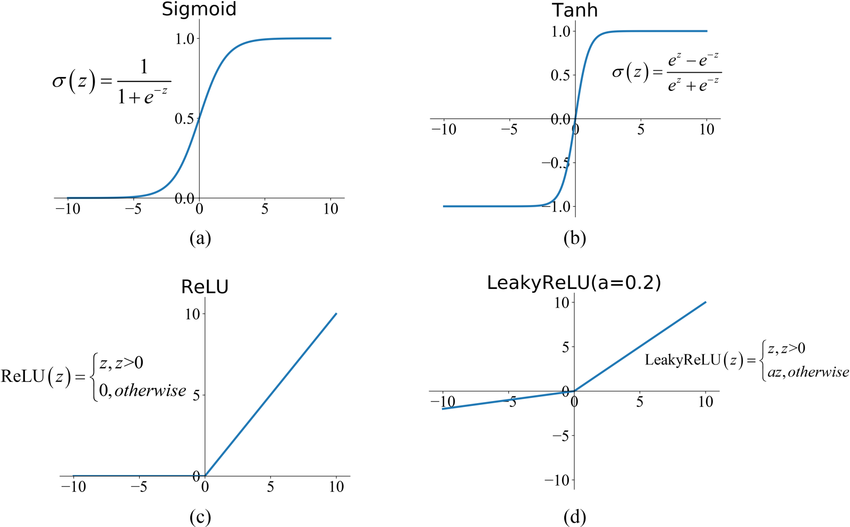
Image Classification
An image is a vector of numbers (pixels)
…linear classifier?
This produces one score per class (cat score, car score, frog score, …), highest score wins. The problem is that each score is just a liner combination of pixel intensities. You can’t draw a flat decision boundary in pixel space! What if the cat moves slightly, or the lighting changes?
better, a multinomial logistic regression (we need probabilities)
Let’s use a Softmax function instead! where
This converts raw class scores into probabilities that sum to 1 Then, we compute loss: , penalizing the model if the correct class has low probability.
Feature extraction
Linear classifiers need data that’s linearly separable. Can we fix this by transforming the data into a new space where it becomes linearly separable? With feature transformations (color histograms, HOGs, bag-of-visual-words, etc…) Works okay, but:
- have to hand-design the transformations
- task-specific (what works for cars might fails for dogs)
- can’t adapt (if dataset changes, have to redesign features manually)
- : the raw input (e.g. pixels, audio wave, text tokens)
- : the learned representation (a non-linear transformation)
- : the prediction or output (class label, next word, etc…)
In DL, itself is learned automatically. Then the final layer can do a simple linear classification .
Neural networks learn the feature extraction for you (representation learning)
Each hidden layer performs a learned feature transformation. The final layer is still a linear classifier, but it now operates on learned features rather than raw pixels. And since the whole system is trained end-to-end (via backpropagation): the network learns whatever features make the final classification easiest.
We cannot teach a model how to pick up the thousands of subtle cues humans use to detect a cat, or a spoken word. Representation learning makes it so that models figure out those perceptual patterns automatically, even ones that humans didn’t even realize were there.
Reusability
The representations learned in one task often generalize to others. The first layers learn reusable “universal” features (edges, corners, colors, textures) The last layers specialize for our specific task (cat or dog?)
Supervised Representation Learning
Training with labeled data, the network learns both how to predict labels and how to represent inputs along the way.
Unsupervised Representation Learning
No labels, the model has to discover structure in the data itself (hopefully with a meaning). Auto-encoders (reconstruct input -> learn compressed representation)
When not to use DL?
- Smaller datasets can be easily solved with hand-crafted features and simpler classifiers.
- Good feature extractors exist (e.g. for tabular data), DL works best on perceptual data (images, speech, language)