Gradient Descent
It’s a technique to solve the optimization problem of Empirical Risk Minimization which just means minimizing the average loss over our dataset.
- : loss for one sample (e.g. how wrong we are on one image)
- : average loss over all training examples
- : model parameters (weights)
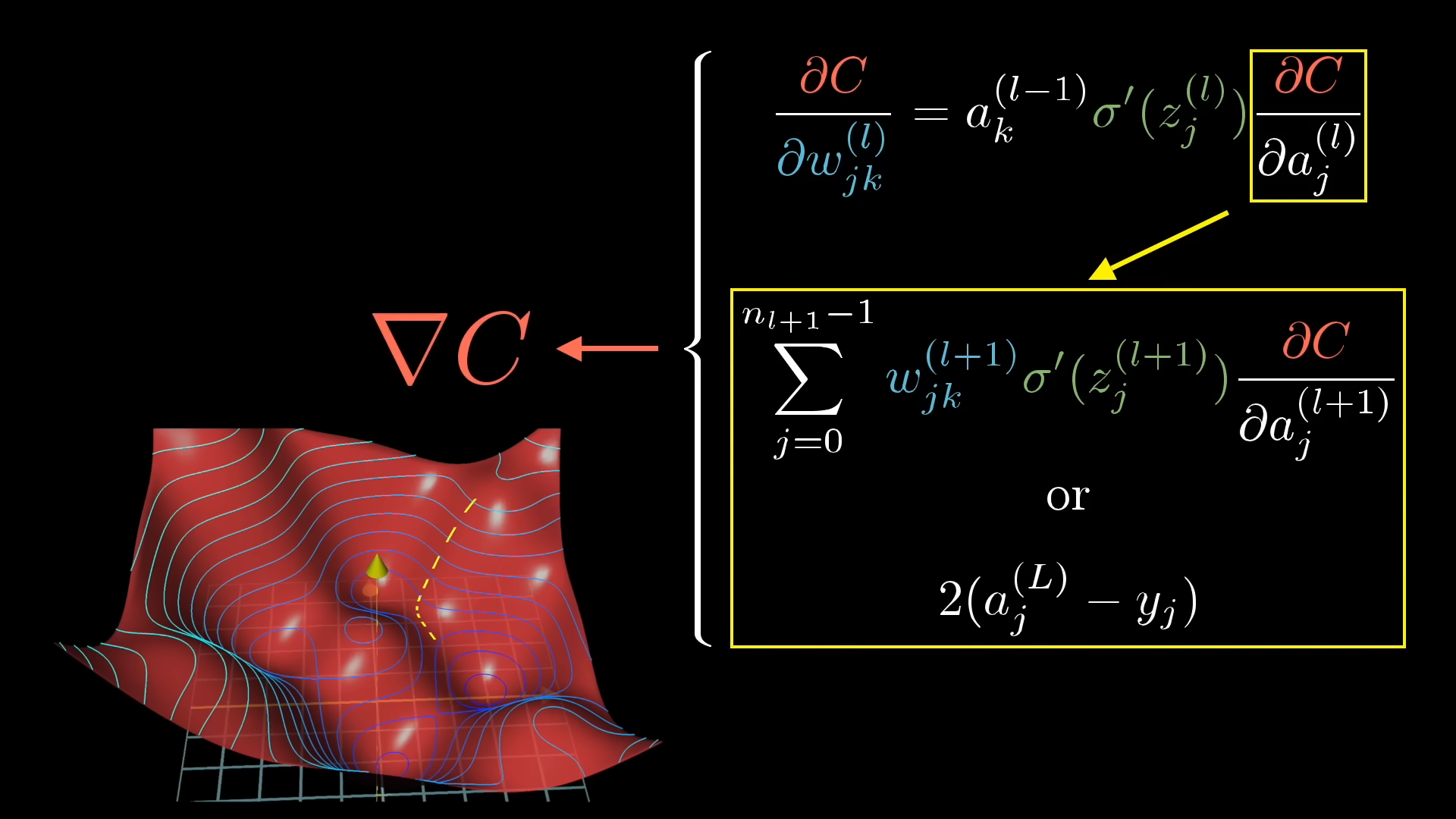
To minimize , we move the parameters a little bit in the direction that makes the loss decrease fastest, that direction is given by the negative gradient of the loss with respect to .
- : vector of partial derivatives (how much each weight affects loss)
- : learning rate (step size)
- : iteration number
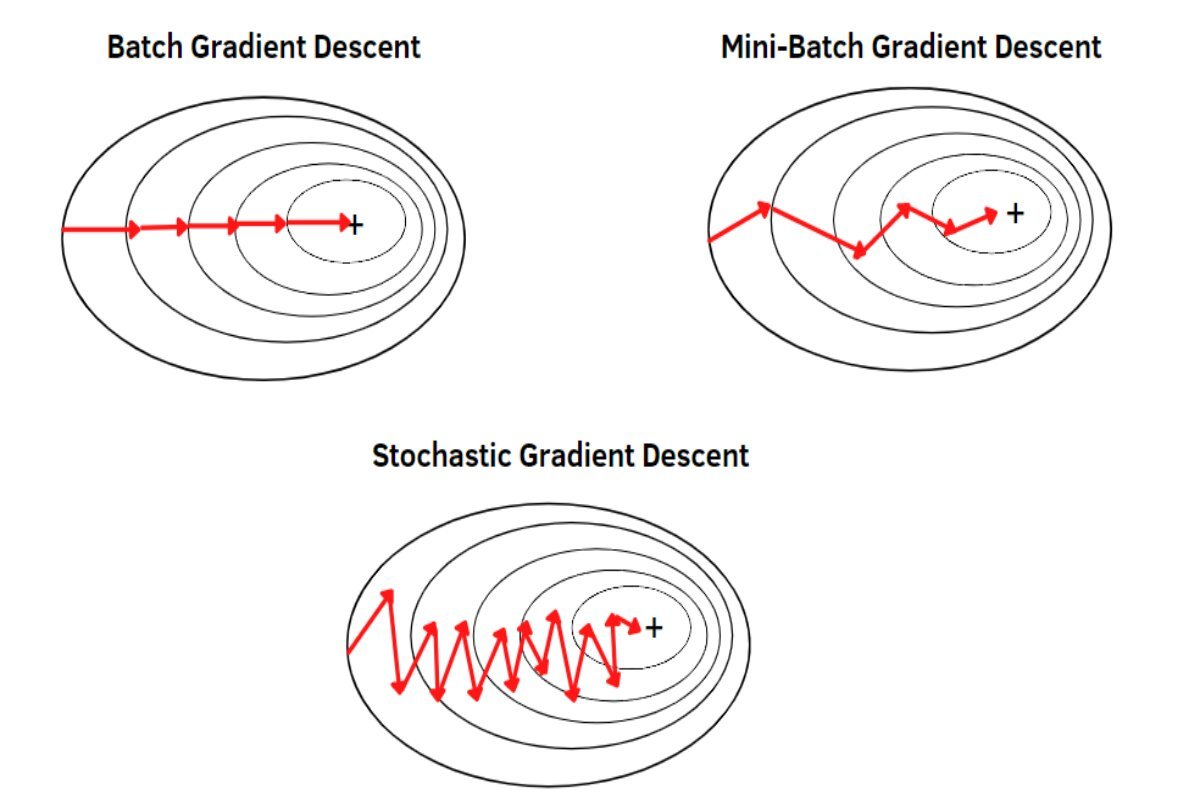
Gradient Descent Variants
- Batch (Full) Gradient Descent
- Compute the gradient using the whole dataset
- Precise but slow (need to pass through all samples before one update) (one update per epoch)
- Stochastic Gradient Descent
- Compute the gradient using one sample at a time
- Noisy but much faster, updates happen every time (one update per sample)
- Mini-Batch SDG
- Compute the gradient on a small subset (e.g. 32 or 64 samples)
- Faster than full batch, more stable than pure SDG (one update per batch)
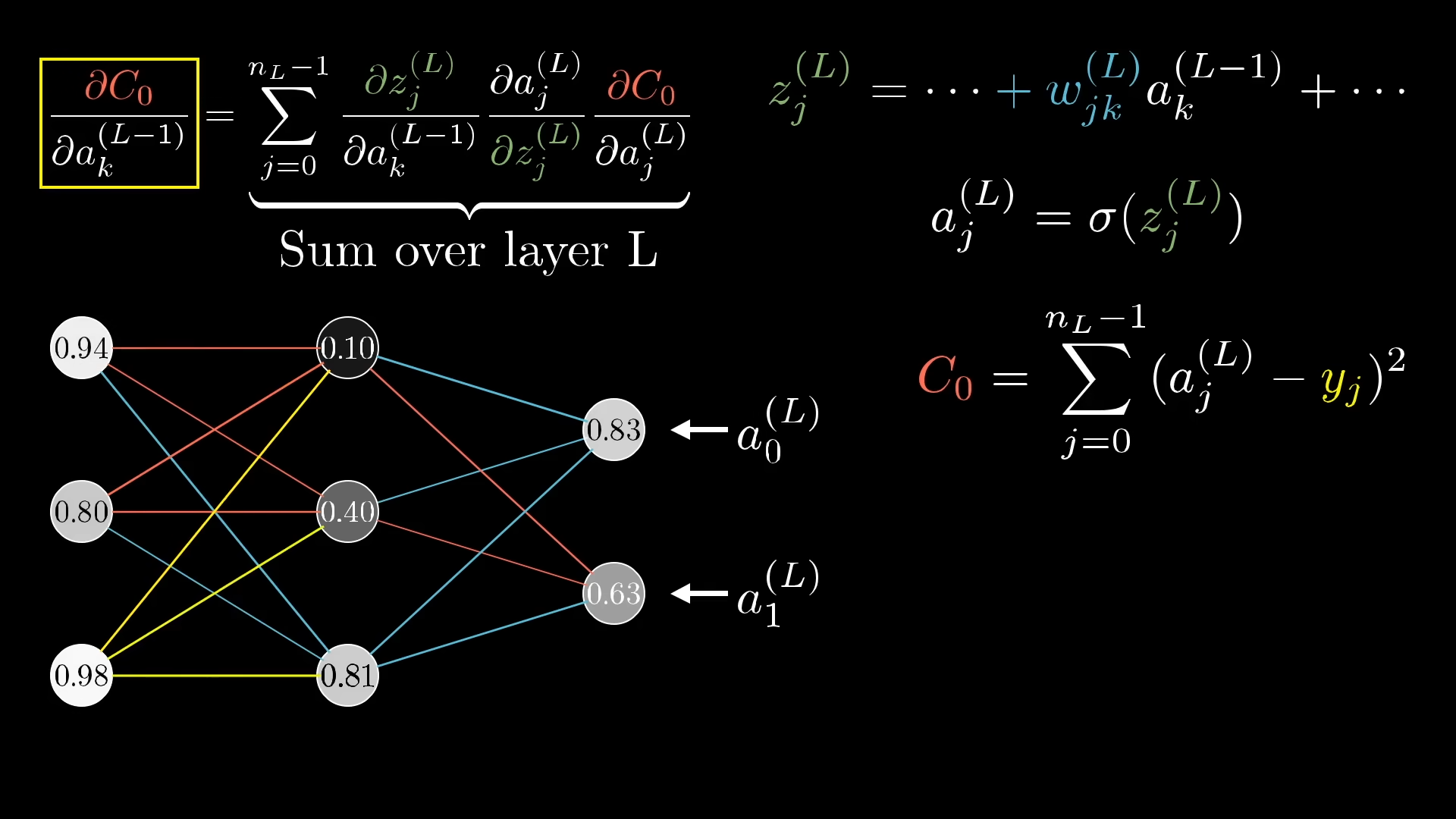
How to compute the gradient?
Finite difference requires forward passes where is the number of parameters.
- Forward difference (1 forward pass per parameter)
- Central difference (2 forward passes per parameter)
Automatic Differentiation
Much more efficient. per layer. We compute derivatives exactly and efficiently by applying the chain rule programmatically.
- Forward-mode AD (compute derivatives and go forward)
- Reverse-mode AD (aka backpropagation)
PyTorch model
import torch
import torch.nn as nn
import torch.optim as optim
# Define model
class Net(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 128)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.relu(self.fc1(x))
return self.fc2(x)
# Instantiate model, loss, optimizer
model = Net()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# Training loop
for X, Y in dataloader:
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, Y)
loss.backward() # <-- backprop (AD)
optimizer.step() # <-- gradient descent update